When to Use Go vs. Java | One Programmer’s Take on Two Top Languages
I can honestly say I have enjoyed working with Java for quite some time now. I built up my expertise in software development working with backend technologies like EJB2, DB2, and Oracle over the last 15 years and last few years while working as a senior, team lead software developer at Spiral Scout, a software development company in San Francisco. Over the years, I moved towards natural language processing-based bots including Spring Boot, Redis, RabbitMQ, Open NLP, IBM Watson, and UIMA. For years, my language of choice was Java and that has worked effectively, even being enjoyable to use at times.
Testing Out Go to Start
In early 2017, I took over a very interesting project that revolved around programming automated systems for monitoring and growing hydroponic plants. The original code base for the software incorporated Go gateways for three different systems — Windows, MacOS, and ARM.
Completely new to Go, my job quickly evolved into a mix of both learning and simultaneously implementing this new language as the project progressed. The challenge was daunting, especially because of the convoluted structure of the existing code base. Supporting a program with platform-specific parts written in CGo for three different operating systems essentially meant deploying, testing, and running maintenance for three different systems. In addition, the code was written with a singleton design pattern making the systems heavily interdependent, often unpredictable, and rather difficult to understand. In the end, I opted to engineer a new version of the gateway with a more Java-esque approach and that too ended up being rather ugly and confounding.
When I moved to Spiral Scout, where I currently serve as a tech lead for one of our biggest U.S. clients, I stopped trying to tap into my Java wheelhouse when developing with Go. Instead, I decided to embrace the language by developing in the most possible Go way and having fun with it. I found it to be an innovative and comprehensive language and our team still uses it daily for a variety of projects.
Like with any programming language, however, Go has its weak points and disadvantages, and I won’t lie, there are times when I really miss Java.
If my experience with programming has taught me anything, it’s that there is no silver bullet when it comes to software development. I’ll detail below how one traditional language and one new kid on the block worked in my experience.
Go vs. Java: The Similarities
Go and Java are both C-family languages which means they share a similar language syntax. That’s why Java developers often find reading Go code fairly easy and vice versa. Go does not use a semicolon (‘;’) symbol at the end of a statement though except in occasional cases where it is needed. To me, the line-delimited statements of Go feel clearer and more readable.
Go and Java also both use one of my favorite features, garbage collector (GC), to help prevent memory leaks. Unlike C++, C-family programmers have to worry about memory leaks and garbage collector is one of those features that automates memory management and therefore simplifies their job.
Go’s GC does not use the Weak Generational Hypothesis, however, it still performs very well and has a very short Stop-the-World (STW) pause. With version 1.5, the STW was reduced even more and essentially became constant, and with version 1.8, it dropped to less than 1ms.
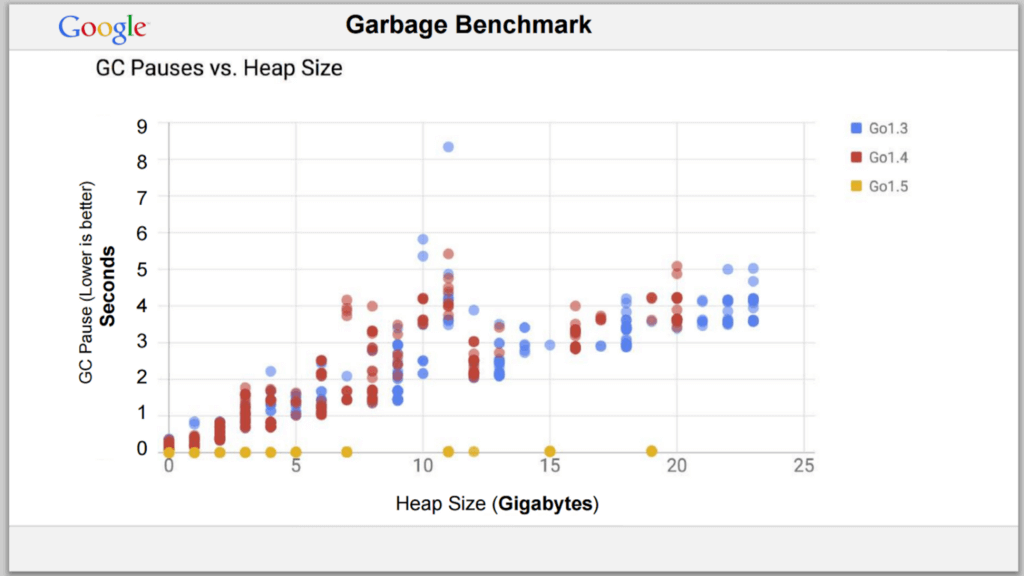
Go’s GC only has a few settings though, i.e. the sole GOGC variable which sets the initial garbage collection target percentage. In Java, you have 4 different garbage collectors and tons of settings for each.
While Java and Go are both considered cross-platform, Java needs the Java Virtual Machine (JVM) to interpret compiled code. Go simply compiles the code into a binary file for any given platform. I actually consider Java less platform-dependent than Go because Go requires you to create a binary file every time you compile code for a single platform. Compiling binaries for different platforms separately is quite time-consuming from a testing and DevOps point of view and cross-platform Go compilation does not work in certain cases, especially when we use CGo parts. Meanwhile, with Java, you can use the same jar anywhere you have the JVM. Go requires less RAM and no additional considerations regarding installing and managing the virtual machine.
Reflection. Unlike Java where reflection is convenient, popular, and commonly used, Go’s reflection seems more complicated and less obvious. Java is an object-oriented language so everything except the primitive is considered an object. If you want to use reflection, you can create a class for the object and get the desired information from the class, like this:
Class cls = obj.getClass();
Constructor constructor = cls.getConstructor();
Method[] methods = cls.getDeclaredFields();
This gives you access to constructors, methods, and properties so that you can invoke or set them.
In Go there is no notion of class and a structure contains only the declared fields. So we need to have the package “reflection” in order to provide the desired information:
type Foo struct {
A int `tag1:"First Tag" tag2:"Second Tag"`
B string
}
f := Foo{A: 10, B: "Salutations"}
fType := reflect.TypeOf(f)
switch t.Kind(fType)
case reflect.Struct:
for i := 0; i < t.NumField(); i++ {
f := t.Field(i)
…..
}
}
I realize this isn’t a huge problem, but since there are no constructors for the structures in Go, the result is many primitive types that have to be processed separately as well as pointers that have to be taken into account. In Go, we can also pass something by pointer or value. The Go structure can have a function as a field, not a method. All this makes the reflection in Go more complex and less usable.
Accessibility. Java has private, protected and public modifiers in order to provide the scopes with different access to the data, methods, and objects. Go has exported/unexported identifiers that are similar to public and private modifiers in Java. There are no modifiers. Anything that starts with an uppercase letter is exported and will be visible in other packages. Unexported — lowercase variables or functions will only be visible from the current package.
Go vs. Java: The Big Differences
Golang is not an OOP language. At its core, Go lacks the inheritance of Java because it does not implement traditional polymorphism by inheritance. In fact, it has no objects, only structures. It can simulate some object-oriented patterns by providing interfaces and implementing the interfaces for structures. Also, you can embed structures to each other but embedded structures do not have any access to the hosting structure’s data and methods. Go uses composition instead of inheritance in order to combine some desired behavior and data.
Go is an imperative language and Java tends to be a declarative language. In Go, we don’t have anything like dependency injection; instead, we have to wrap up everything together explicitly. That’s why the recommended approach to programming in Go is to use as little magic as possible. Everything should be really obvious for an external code reviewer and a programmer should understand all the mechanisms for how the Go code uses the memory, file system, and other resources.
Java, on the other hand, requires more of a developer’s attention toward custom-writing the business logic portion of a program to determine how data is created, filtered, changed, and stored. As far as the system infrastructure and database management are concerned — all that is done by configuration and annotations via generic frameworks like Spring Boot. We concern ourselves less with the boring droll of repeating infrastructure parts and leave that to the framework. This is convenient but also inverts control and limits our ability to optimize the overall process.
The order of the variable’s definition. In Java you can write something like:
String name;
. . . but in Go you would write
name string
This was obviously confusing when I first started working with Go.
The Pros of Using Go
Simple and elegant concurrency. Go has a powerful model of concurrency called “communicating sequential processes” or CSP. Go uses an n-to-m profiler which allows m concurrent executions to happen in n system threads. The concurrent routine can be started in a very basic way simply using the keywords of the language, the same as the language’s name. For example, a coder can write the string:
go doMyWork()
... and the function doMyWork() will start executing concurrently.
The communication between the processes can be done with the shared memory (not recommended) and channels. It allows for very robust and fluid parallelism that uses as many cores of the processes as we define with the GOMAXPROCS environment variable.
By default, the number of processes is equal to the number of cores.
Go provides a special mode to run binary with a check for run race situations. This way, you can test and prove that your software is concurrency safe.
go run -race myapp.go
This will run the application in run race detection mode.
I really appreciate that Go provides very useful, basic functionality right out-of-the-box. One go-to example of this is the synchronization “sync” package for concurrency. For “Once” group type singleton implementations you can write:
package singleton
import (
"sync"
)
type singleton struct {
}
var instance *singleton
var once sync.Once
func GetInstance() *singleton {
once.Do(func() {
instance = &singleton;{}
})
return instance
}
Package sync also provides a structure for concurrent map implementation, mutexes, condition variables, and wait groups. Package “atomic” additionally allows for concurrency safe conversion and math operations — essentially everything we need for making a concurrency ready code.
Pointers. With pointers, Go allows for more control over how to allocate memory, garbage collector payload, and other interesting performance tweaks that are impossible with Java. Go feels like a more low-level language than Java and favors much easier and faster performance optimizations.
Duck typing. “If it walks like a duck and it quacks like a duck, then it must be a duck.” This saying holds true with Go: there is no need to define that a certain structure implements a given interface. If the structure has the methods with the same signatures in a given interface then it implements it. This is very helpful. As the client of a library, you can define any interfaces you need for external libraries structures. In Java, an Object has to explicitly declare that it implements the interface.
The profiler. Go’s profiling tools make analyzing performance issues convenient, quick and easy. The profiler in Go helps reveal the memory allocations and CPU usage for all parts of a program and can illustrate them in a visual graph making it extremely easy to take action around optimizing performance. Java also has many profilers, starting from Java VisualVM, but they are not as simple as the Go profiler. Their efficacy instead depends on the work of the JVM so the statistics obtained from them correlates with the work of the garbage collector.
CGO. Go allows for a very simple yet powerful integration of C so you are able to write platform-dependent applications with snippets of C code inside of your Go project. Essentially, CGo enables developers to create Go packages that call C code. There are various builder options in order to exclude/include C code snippet for a given platform which allows for multi-platform realizations of applications.
Function as an argument. A Go function may be used as a variable, passed into another function or serve as a field of a structure. This versatility is refreshing. Starting from 1.8 version of Java, it incorporates the use of lambdas, they are not really functions, but one-function objects. While this facilitates a behavior similar to using functions in Go, the idea existed in Go from the very beginning.
Clear guidelines for the code style. The community behind Go is supportive and passionate. There is a ton of information out there about the best Go-way to do things with examples and explanations https://golang.org/doc/effective_go.html.
Functions can return many arguments. This is also quite useful and nice.
package main
import "fmt"
func returnMany() (int, string, error) {
return 1, "example", nil
}
func main() {
i, s, err := returnMany()
fmt.Printf("Returned %s %s %v", i, s, err)
The Cons of Using Go
No polymorphism except with interfaces. There is no ad-hoc polymorphism in Go which means if you have two functions in the same package with different arguments but the same sense, then you will have to give them different names. For example, with this code . . .
func makeWorkInt(number int) {
fmt.Printf(“Work done number %d”, number)
}
func makeWorkStr(title string) {
fmt.Printf(“Work done title %s”, title)
}
... you wind up with many methods doing the same thing but all with different and ugly names.
Additionally, there is no polymorphism by inheritance. If you embed a structure then the embedded structure knows only its own methods, it does not know the methods of the “hosting” structure. This is particularly challenging for developers like me who transitioned to Go after working mostly with an OOP language where one of the most basic concepts is inheritance.
But, over time I started to realize that this approach to polymorphism is just another way of thinking and makes sense because, in the end, the composition is more reliable, evident and run time is changeable.
Errors handling. It is completely up to you what errors are returned and how they are returned, so as the developer, you need to return the error every time and pass it up accordingly. Unsurprisingly, errors may be hidden, which can be a real pain. Remembering to check for errors and pass them up feels annoying and unsafe.
Of course, you can use a linter to check for hidden errors, but that is more of a patch and not a real solution. In Java, exceptions are much more convenient. You don’t even have to add it to a function’s signature if it is a RuntimeException.
public void causeNullPointerException() {
throw new NullPointerException("demo");
}
……...
try {
causeNullPointerException() ;
}
catch(NullPointerException e) {
System.out.println("Caught inside fun().");
throw e; // rethrowing the exception
No generics. While convenient, generics add complexity and were considered costly to Go creators when it came down to type system and run time. When building in Go you essentially have to repeat yourself for different types or use code generation.
No annotations. While the compile-time annotations can be partially substituted with code generation, unfortunately, the runtime annotations cannot be substituted at all. This makes sense because Go is not declarative and there shouldn’t be any magics in the code.
I liked using annotations in Java though because they made the code much more elegant, simple and minimalistic.
They would be very useful in providing some aspects or metadata for the HTTP server endpoints with swagger file generation later on. In Go, you currently have to make the swagger file manually or directly or provide special comments for the endpoints functions. This is quite a pain every time you change your API. However, annotations in Java is a kind of magic where people often do not care how they work exactly.
Dependency management in Go. I previously wrote about dependency management in Go using vgo and dep. This is a great synopsis of the issues and describes my biggest issue with Go and honestly, I’m not the only one who feels this way. The Go dependency management landscape has looked rather rocky for some time. Initially, there was no dependency management beyond “Gopgk” but the “Vendor” experiment released eventually which was later replaced with “vgo” and then further replaced with version 1.10, “go mod”. Nowadays the go.mod file descriptor can be changed both manually as well as with various Go commands, like “go get”; this, unfortunately, makes the dependencies unstable.
There is also no mirroring of the sources provided by the dependency management mechanism out of the box. It’s somewhat of a pity especially because Java has awesome declarative tools for dependency management like Maven and Gradle that also serve to build, deploy, and handle other CD/CI purposes. We effectively have to custom-build the dependency management we want using Makefiles, docker-composes, and bash scripts, which only complicates the CD/CI process and stability.
Go microservices often start in containers and end the same time locally and in a virtual Linux machine or at different platforms. Sometimes it makes the CD/CI work for development and production cycles more complicated than it needs to be.
The name of the packages includes the hosting domain name.
For example:
import "github.com/pkg/errors"
This is really strange and especially inconvenient since you cannot replace someone’s implementation with your own implementation without changing imports over the entire projects code base.
In Java, the imports often start with the company name, like:
import by.spirascout.public.examples.simple.Helper;
The difference is that in Go, the go get will go to by.spirascout.public and try to get the resource. In Java, the package and domain names do not have to correlate.
I do hope that all the problems with dependency management are temporary and will be resolved in the most effective way in the future.
Final Thoughts
One of the most interesting aspects of Go is the code naming guidelines it follows. They were based on the psychology of code readability approach (check out this article).
With Go, you can write very clear and maintainable code with separated approaches and while it is a language of many words, it still remains clear and evident.
Working at a Golang web development company has clearly shown me that Go is fast, robust, and easy to understand which makes it very good for small services and concurrent processing. For large, intricate systems, services with more complex functionality, and single-server systems, Java will hold its own among the top programming languages in the world for the time being.
While Java SE has become payable, Go is truly a child of the programming community. Actually, there are a ton of different brand JWMs, but Go’s toolset is the same one.
Bottom line: Different tasks need different tools.