
Understanding Concurrency and Parallelism in Golang
When it comes to human cognitive abilities, few concepts come up for as much debate as “multitasking.” Multitasking requires vast amounts of cognitive processing and allows humans to both tap into memory reserves while simultaneously projecting into the future.
The idea of multitasking sparks controversy, however, with one school of thought claiming it’s a human feat that separates us from all other animals, and another school of thought claiming the human brain is incapable of performing more than one high-level brain function at the same time.
What science has undoubtedly proven, however, is that humans do have the ability to rapidly switch between tasks and successfully shift focus from one thing to the other.
Multitasking plays a similar role in computing but takes on a couple of different names - concurrency and parallel processing.
Concurrency and Parallel Processing
In software development, concurrency and parallelism usually occur in applications with multithreading. It’s important to know the significant, albeit nuanced, difference between the two processes. Consider the metaphor, for example, of a team of workers building a car.
With concurrency, you can have multiple workers building different parts for the car, but they share one common bench for assembling the parts. Only one worker can assemble at the bench at a time, so while one does, the other workers operate on their parts in the background. With parallelism, you have multiple benches at which workers can be assembling parts simultaneously.
Golang and Concurrency
As a general concept, concurrency is widely known and used throughout the Go community. The key to achieving Golang concurrency is using Goroutines - lightweight, low-cost methods or functions that can run concurrently with other methods and functions. Golang offers a specific CSP (Communication Sequential Processes) paradigm in its base, which allows for convenient parallel processing using Goroutines to facilitate concurrent execution in code. It effectively acts as a “scheduler” which maps a fixed number of system threads to execute a potentially infinite number of Goroutines. What does this mean for developers? You can write concurrent code that can be executed in parallel by different cores of the computer or executed in sequence, depending on the runtime of your Go scheduler. Concurrency in Golang typically happens when Go channels exchange data between Goroutines, which sounds promising and straightforward enough. But how exactly can a developer structure the code so it is internally consistent and does not have race-conditions? In this post, I will describe some patterns we use widely as a Golang software development company for parallelizing the processing of data in our microservices. Usually, we use parallelization by algorithm or parallelization by data to power many processor cores of the hosting computer and speed up computations.
Parallelization by Algorithm
Parallelization by algorithm means that a program contains different stages that can be executed independently. In most cases, one stage depends on another stage or data that stage produces. A helpful example would be to look at computational and transmitting tasks. The computational task should not be blocked by the transmitting task in the code, so it is better to run them in parallel. Usually, we use the following pattern in order to relate and run the tasks:
package main
import "fmt"
type Figure struct {
Length int
Width int
Square int
}
const n = 2
func main() {
ff := []Figure{Figure{1, 2, 0}, Figure{3, 2, 0}, Figure{1, 10, 0}}
squarec := make(chan Figure, n)
go func() {
computeSquare(ff, squarec)
}()
send(squarec)
}
func computeSquare(ff []Figure, squarec chan<- Figure) {
for _, f := range ff {
f.Square = f.Length * f.Width
squarec <- f
}
close(squarec)
}
func send(sourcec <-chan Figure) {
count := 0
batch := make([]Figure, 0, n)
for f := range sourcec {
batch = append(batch, f)
count++
if count == n {
// imitate sending batch
fmt.Println(batch)
batch = make([]Figure, 0, n)
count = 0
}
}
// imitate sending rest
fmt.Println(batch)
}
First, we run the routine for calculating the square of a figure computeSquare. Then we run the sending task. And when we finish computing the data, we close the communication channel using squarec. The transmission of the data finishes when all the data is received from the channel, and the channel is closed.
What size of buffer should we use for the channel squarec := make(chan Figure, n? It primarily depends on the transmission mechanism. If the sending of the data is regular, one-by-one, then it does not make sense to have a buffered channel. If the data is sent by batches, so the transport collects a batch and then sends it, then we should put n=batchSize. Also, it makes sense to have n>0 if we want to investigate which task is taking the longest amount of time - data computation or transport.
After we choose what size buffer we need, we can run the code with a block profiler. If the channel with the buffer is still blocked, then the transmission of the data is slower than the computations. On the other hand, if the computation is slower, we can still optimize it to make the overall process work faster.
Please note, the channel should always be closed by the component that has the responsibility for sending the data to the channel (function computeSquare). This way, we will never have to worry about the channel being closed when we are trying to send data to it.
If there is a chain of subtasks we want to parallelize, we want to put them in the chain in a similar way:
package main
import (
"fmt"
)
type Figure struct {
Length int
Width int
Height int
Square int
Volume int
}
const n = 2
func main() {
ff := []Figure{
Figure{1, 2, 5, 0, 0},
Figure{3, 2, 4, 0, 0},
Figure{1, 10, 3, 0, 0}}
squarec := make(chan Figure, n)
volumec := make(chan Figure, n)
go func() {
computeSquare(ff, squarec)
}()
go func() {
computeVolume(squarec, volumec)
}()
send(volumec)
}
func computeSquare(ff []Figure, squarec chan<- Figure) {
for _, f := range ff {
f.Square = f.Length * f.Width
squarec <- f
}
close(squarec)
}
func computeVolume(squarec <-chan Figure, volumec chan<- Figure) {
for f := range squarec {
f.Volume = f.Square * f.Height
volumec <- f
}
close(volumec)
}
func send(sourcec <-chan Figure) error {
count := 0
batch := make([]Figure, 0, n)
for f := range sourcec {
batch = append(batch, f)
count++
if count == n {
// imitate sending batch
fmt.Println(batch)
batch = make([]Figure, 0, n)
count = 0
}
}
// imitate sending rest
fmt.Println(batch)
return nil
}
This way, both of the stages for computations computeSquare and computeVolume run concurrently with the task of sending the data. Very often, a calculation may fail, and in these cases, the code should provide a way to return an error code and stop processing. How would our code look if each of the tasks return an error?
package main
import (
"fmt"
"sync"
)
type Figure struct {
Length int
Width int
Height int
Square int
Volume int
}
const (
n = 2
statusOK = 0
statusError = 1
)
func main() {
errc := make(chan error)
status := statusOK
errGroup := sync.WaitGroup{}
errGroup.Add(1)
go func() {
for err := range errc {
status = statusError
fmt.Printf("error processing the code: %s\n", err)
}
errGroup.Done()
}()
ff := []Figure{
Figure{1, 2, -5, 0, 0},
Figure{3, 2, 4, 0, 0},
Figure{1, 10, 3, 0, 0},
Figure{1, 10, -3, 0, 0},
Figure{-1, 10, 3, 0, 0},
Figure{1, 10, 3, 0, 0}}
squarec := make(chan Figure, n)
volumec := make(chan Figure, n)
go func() {
computeSquare(ff, squarec, errc)
}()
go func() {
computeVolume(squarec, volumec, errc)
}()
send(volumec, errc)
close(errc)
errGroup.Wait()
}
func computeSquare(ff []Figure, squarec chan<- Figure, errc chan<- error) {
for _, f := range ff {
if f.Length <= 0 || f.Width <= 0 {
errc <- fmt.Errorf("invalid length or width value, should be positive non-zero, length: %d, width: %d", f.Length, f.Width)
}
f.Square = f.Length * f.Width
squarec <- f
}
close(squarec)
}
func computeVolume(squarec <-chan Figure, volumec chan<- Figure, errc chan<- error) {
var err error
for f := range squarec {
if f.Height <= 0 {
err = fmt.Errorf("invalid height value, should be positive non-zero, height: %d", f.Height)
errc <- err
}
// skip if error happens during previous figure calculation
if err == nil {
f.Volume = f.Square * f.Height
volumec <- f
}
}
close(volumec)
}
func send(sourcec <-chan Figure, errc chan<- error) { var err error count := 0 batch := make([]Figure, 0, n) for f := range sourcec { if f.Volume > 25 {
err = fmt.Errorf("cannot send figures with volume more than 25, volume: %d", f.Volume)
errc <- err
}
// skip if error happens during sending
if err == nil {
batch = append(batch, f)
count++
if count == n {
// imitate sending batch
fmt.Println(batch)
batch = make([]Figure, 0, n)
count = 0
}
}
}
if err == nil && len(batch) != 0 {
// imitate sending rest
fmt.Println(batch)
}
}
This code becomes a bit more complicated. First of all, we need to introduce an additional channel for errors errc and the new Goroutine to read errors from the channel. Then we need to have the errGroup waitgroup in order to allow for a graceful shutdown of the code once all the errors are retrieved and printed. It will happen when we close the error channel at the end of the main function.
Please also note that computeSquare only exists when it encounters an error, but computeVolume continues looping on the input channel squarec because, otherwise, computeSquare would be blocked from writing to the channel. Thus, computeVolume reads all the data from the channel squarec independently from errors at the stage. The same happens at the sending task - despite the errors in sending, it reads all the incoming data from the input channel.
Parallelization by Data
The second way to parallelize the code is to do it by data. This happens when we have an array of input data, and the data items can be processed independently. They do not depend on or correlate with each other. The easiest way to achieve parallelization by data is to use WaitGroup from the sync package.
Let’s consider, however, the case in which a calculation step may return an error when processing data. There is a standard mechanism for this - Group from errgroup package:
https://godoc.org/golang.org/x/sync/errgroup.
We are going to complicate our previous example from the beginning of this post and, in addition to parallel processing by algorithm, now conduct parallel processing by data. Essentially, we are going to use Goroutines to calculate both volume and square at the same time and send the results back in parallel.
In the previous example, we executed the Square, Volume, and Send functions concurrently; but, the data was iterated and processed one-by-one in the Square and Volume steps. Now, however, we will process every Figure simultaneously.
This is how it was before:
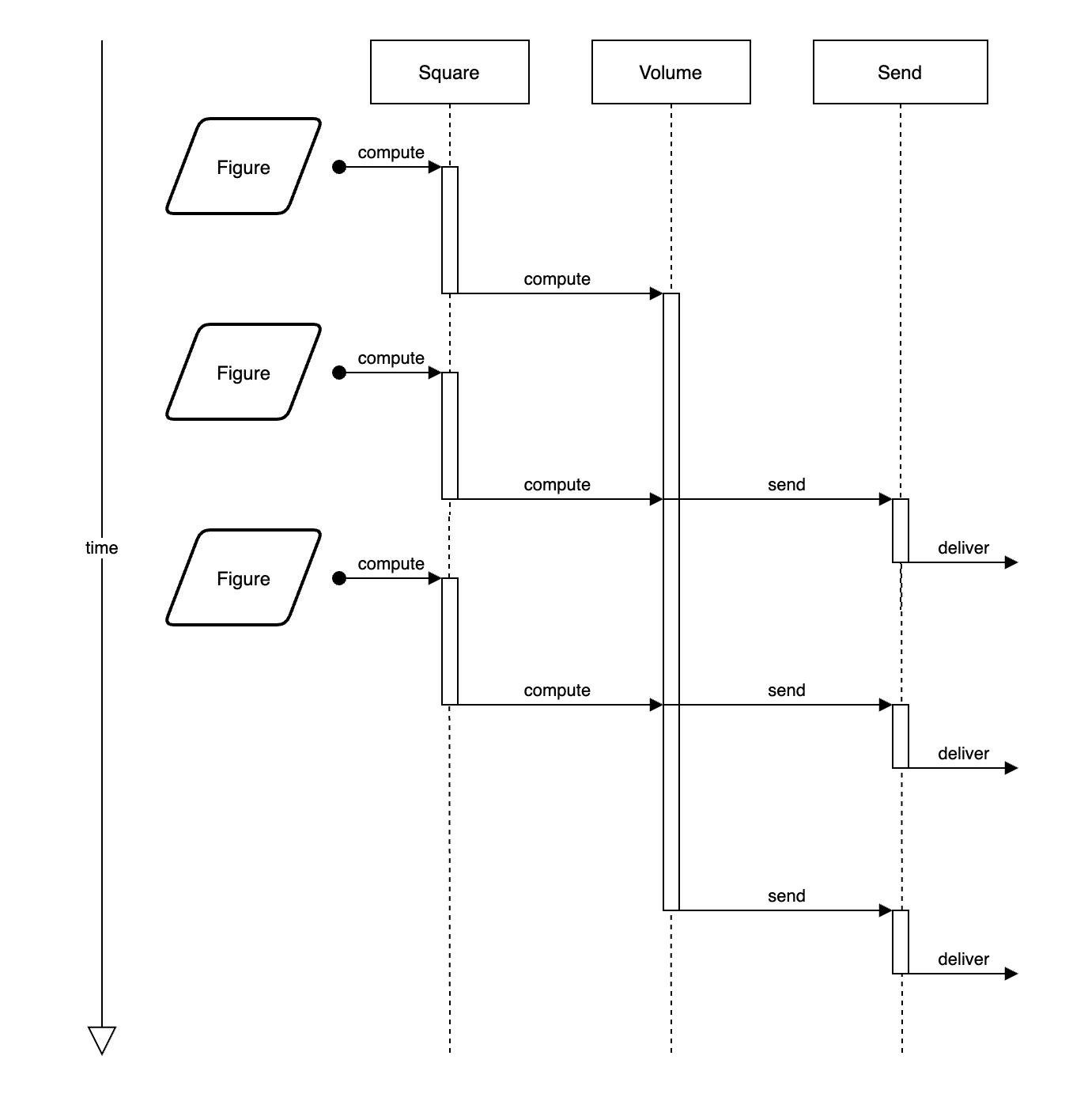
This is how we are going to do it here:
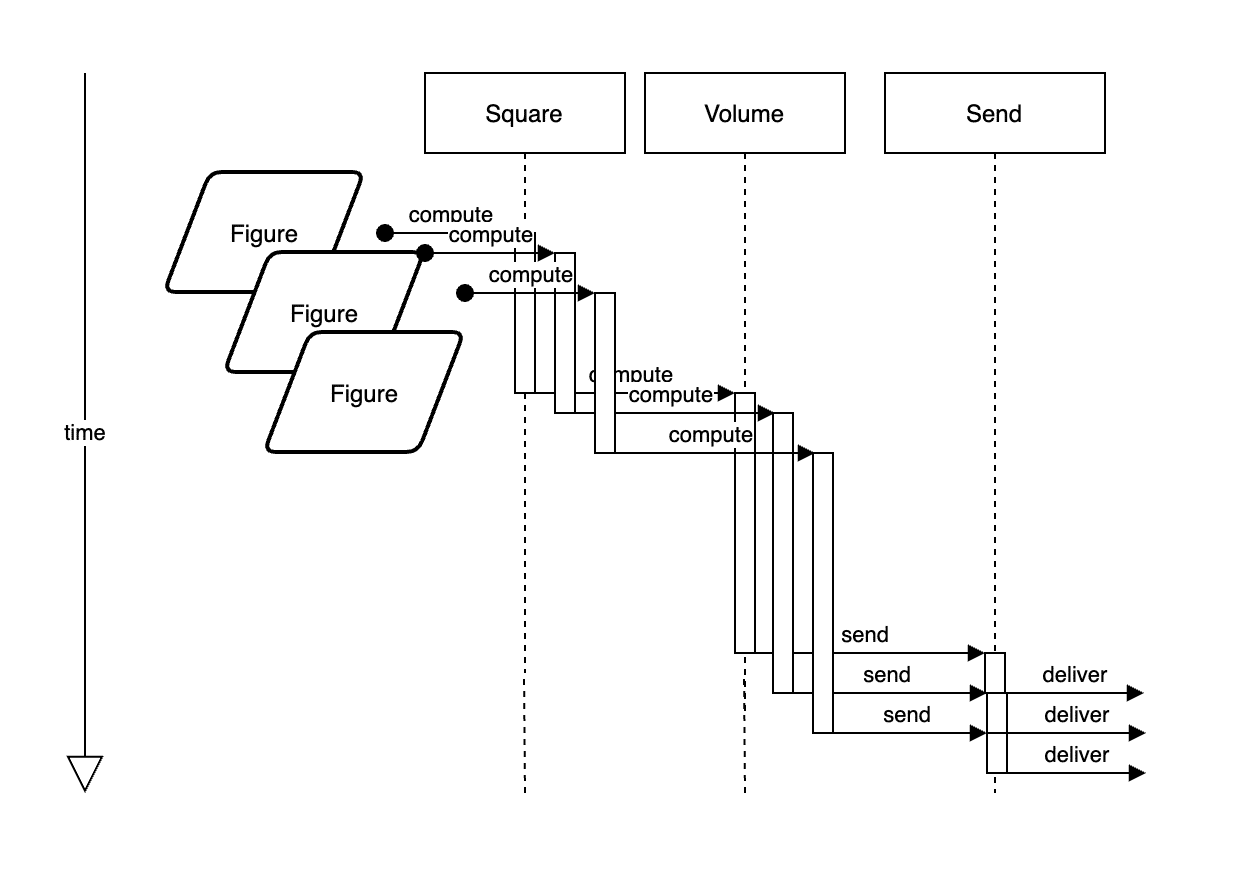
package main
import (
"fmt"
"sync"
"golang.org/x/sync/errgroup"
)
type Figure struct {
Length int
Width int
Height int
Square int
Volume int
}
const (
n = 2
statusOK = 0
statusError = 1
)
func main() {
errc := make(chan error)
status := statusOK
errProcess := sync.WaitGroup{}
errProcess.Add(1)
go func() {
for err := range errc {
status = statusError
fmt.Printf("error processing the code: %s\n", err)
}
errProcess.Done()
}()
ff := []Figure{
Figure{1, 2, -5, 0, 0},
Figure{3, 2, 4, 0, 0},
Figure{1, 10, 3, 0, 0},
Figure{1, 10, -3, 0, 0},
Figure{-1, 10, 3, 0, 0},
Figure{1, 10, 3, 0, 0}}
squarec := make(chan Figure, n)
volumec := make(chan Figure, n)
go func() {
if err := computeSquare(ff, squarec); err != nil {
errc <- err
}
close(squarec)
}()
go func() {
if err := computeVolume(squarec, volumec); err != nil {
errc <- err
}
close(volumec)
}()
send(volumec, errc)
close(errc)
errProcess.Wait()
}
func computeSquare(ff []Figure, squarec chan<- Figure) error {
eg := errgroup.Group{}
for _, f := range ff {
fClosure := f
eg.Go(func() error {
if fClosure.Length <= 0 || fClosure.Width <= 0 {
return fmt.Errorf("invalid length or width value, should be positive non-zero, length: %d, width: %d", fClosure.Length, fClosure.Width)
}
fClosure.Square = fClosure.Length * fClosure.Width
squarec <- fClosure
return nil
})
}
return eg.Wait()
}
func computeVolume(squarec <-chan Figure, volumec chan<- Figure) error {
eg := errgroup.Group{}
for f := range squarec {
fClosure := f
eg.Go(func() error {
if fClosure.Height <= 0 {
return fmt.Errorf("invalid height value, should be positive non-zero, height: %d", fClosure.Height)
}
fClosure.Volume = fClosure.Square * fClosure.Height
volumec <- fClosure
return nil
})
}
return eg.Wait()
}
func send(sourcec <-chan Figure, errc chan<- error) { var err error count := 0 batch := make([]Figure, 0, n) for f := range sourcec { if f.Volume > 25 {
err = fmt.Errorf("cannot send figures with volume more than 25, volume: %d", f.Volume)
errc <- err
}
// skip if error happens during sending
if err == nil {
batch = append(batch, f)
count++
if count == n {
// imitate sending batch
fmt.Println(batch)
batch = make([]Figure, 0, n)
count = 0
}
}
}
if err == nil && len(batch) != 0 {
// imitate sending rest
fmt.Println(batch)
}
}
Since errgroup returns only one error, we send only this error to the error channel. Please note, we copy the figure in the calculation functions to fClosure variable. It is because the errgroup receives the closure of variable f, and the variable from the “for” loop will always be changing. Thus we would have incorrect values in the closure. The program gives us non-deterministic results because the data is processed concurrently, and the code does not guarantee that we will receive the output in the same sequence as the input. The algorithm with the groups will create as many Goroutines as the data items you have in the input. This may not be optimal from the point of view of RAM and CPU usage, and it can slow down the overall performance of large data inputs specifically. In those cases, however, we usually use workers; and since our stages return errors, then we make sure to use errored workers. We use our own implementation of the errored worker:
package errworker
import (
"sync"
)
type ErrWorkgroup struct {
limiterc chan struct{}
wg sync.WaitGroup
errMutex sync.RWMutex
err error
skipWhenError bool
}
func NewErrWorkgroup(size int, skipWhenError bool) ErrWorkgroup {
if size < 1 {
size = 1
}
return ErrWorkgroup{
limiterc: make(chan struct{}, size),
skipWhenError: skipWhenError,
}
}
// Wait waits till all current jobs finish and returns first occurred error
// in case something went wrong.
func (w *ErrWorkgroup) Wait() error {
w.wg.Wait()
return w.err
}
// Go adds work func with error to the ErrWorkgroup. If err occurred other jobs won't proceed.
func (w *ErrWorkgroup) Go(work func() error) {
w.wg.Add(1)
go func(fn func() error) {
w.limiterc <- struct{}{} if w.skipWhenError { // if ErrWorkgroup corrupted -> skip work execution
w.errMutex.RLock()
if w.err == nil {
w.errMutex.RUnlock()
w.execute(fn)
} else {
w.errMutex.RUnlock()
}
} else {
w.execute(fn)
}
w.wg.Done()
<-w.limiterc
}(work)
}
func (w *ErrWorkgroup) execute(work func() error) {
if err := work(); err != nil {
w.errMutex.Lock()
w.err = err
w.errMutex.Unlock()
}
}
This worker group can accept an unlimited number of tasks but executes only a number of tasks given in the constructor func NewErrWorkgroup(size int, skipWhenError bool) in any single moment. This worker pool does not execute the rest of the incoming tasks if some of the tasks fail; to bypass this, we specify skipWhenError=true. This is done by the check of the error protected by the mutex, errMutex. Mutex refers to a mutual exclusion object which enables multiple program threads to share the same resource like a variable or data resource, but not simultaneously. When a program is started, a mutex is created with a unique name, in this case, errMutex. This protects the places to which the Goroutines are reading and writing and prevents race conditions from occurring (and causing bugs in the code). Note: The Mutex is available in the sync package and acts as a locking mechanism to ensure that only one Goroutine is running a critical section of code at a given time.
As you can see, the worker uses the limiterc channel to limit the number of workers. So all the tasks stay as idling (blocked) Goroutines and do not consume CPU.
The code with the worker will look like the following:
package main
import (
"fmt"
"github.com/guntenbein/goconcurrency/errworker"
"sync"
)
type Figure struct {
Length int
Width int
Height int
Square int
Volume int
}
const (
n = 2
statusOK = 0
statusError = 1
)
func main() {
errc := make(chan error)
status := statusOK
errGroup := sync.WaitGroup{}
errGroup.Add(1)
go func() {
for err := range errc {
status = statusError
fmt.Printf("error processing the code: %s\n", err)
}
errGroup.Done()
}()
ff := []Figure{
Figure{1, 2, 5, 0, 0},
Figure{3, 2, 4, 0, 0},
Figure{1, 10, 3, 0, 0},
Figure{1, 10, -3, 0, 0},
Figure{1, -10, 3, 0, 0},
Figure{1, 10, 5, 0, 0}}
squarec := make(chan Figure, n)
volumec := make(chan Figure, n)
go func() {
if err := computeSquare(ff, squarec); err != nil {
errc <- err
}
close(squarec)
}()
go func() {
if err := computeVolume(squarec, volumec); err != nil {
errc <- err
}
close(volumec)
}()
send(volumec, errc)
close(errc)
errGroup.Wait()
}
func computeSquare(ff []Figure, squarec chan<- Figure) error {
ew := errworker.NewErrWorkgroup(2, true)
for _, f := range ff {
fClosure := f
ew.Go(func() error {
if fClosure.Length <= 0 || fClosure.Width <= 0 {
return fmt.Errorf("invalid length or width value, should be positive non-zero, length: %d, width: %d", fClosure.Length, fClosure.Width)
}
fClosure.Square = fClosure.Length * fClosure.Width
squarec <- fClosure
return nil
})
}
return ew.Wait()
}
func computeVolume(squarec <-chan Figure, volumec chan<- Figure) error {
ew := errworker.NewErrWorkgroup(3, true)
var err error
for f := range squarec {
fClosure := f
ew.Go(func() error {
if fClosure.Height <= 0 {
err = fmt.Errorf("invalid height value, should be positive non-zero, height: %d", fClosure.Height)
return err
}
fClosure.Volume = fClosure.Square * fClosure.Height
volumec <- fClosure
return nil
})
}
return ew.Wait()
}
func send(sourcec <-chan Figure, errc chan<- error) { var err error count := 0 batch := make([]Figure, 0, n) for f := range sourcec { if f.Volume > 40 {
err = fmt.Errorf("cannot send figures with volume more than 25, volume: %d", f.Volume)
errc <- err
}
// skip if error happens during sending
if err == nil {
batch = append(batch, f)
count++
if count == n {
// imitate sending batch
fmt.Println(batch)
batch = make([]Figure, 0, n)
count = 0
}
}
}
if err == nil && len(batch) != 0 {
// imitate sending rest
fmt.Println(batch)
}
}
Structurally, it doesn’t make much of a difference with the code if we use the error waitgroup. It does help us conserve RAM and CPU, however, because we run everything in parallel, and this allows us to distribute the resources in the right way. Assume that calculation volume takes more time than square. We can balance it by giving the tasks to volume stage 3 workers and square stage 2 workers. With Go concurrent programming, we always test with -race flag in order to uncover information about race conditions in the code. This is a handy feature of Go because it allows for discovering race conditions in the very early stages of software development. Please visit the following link to access the entire repository for the code shared in this post over on GitHub: https://github.com/guntenbein/goconcurrency